%20-%20Kopia_profile_profilesmall.jpg) Bingen Galartza Iparragirre
Bingen Galartza Iparragirre
Zalantzarik ez daukat artikulu hau irakurtzen ari zareten guztiok ezagutzen duzuela Wordle bideojokoa. Baliteke, gainera, jokora guztiz engantxatuta edo jada aspertuta egotea sare sozialetan jokoaz matraka ematen duten horietaz. Baina, haren berri ez baduzu, labur-labur azalduko dizut: egunero aurrez aukeratutako hitz bat asmatu behar dute jokalariek. Hitza asmatzeko, sei saiakera egin daitezke, eta horietako bakoitzean zein letra asmatu duzun eta zein ez esaten dizu jokoak. Baita letra jarri duzun tokia zuzena den ere esango dizu.
Hitza ahalik eta saiakera gutxien eginda asmatzea da erronka, eta horretarako ezinbestekoak dira adimena, estrategia eta hiztegi zabala edukitzea. Gaurkoan, baina, puzzle horiek asmatzeko beste metodo bat azaldu nahi dizuet: GNU/Linuxeko komando-lerroa erabiltzea hitzak errazago aurkitzeko.
Norbaitek pentsa lezake Wordlen tranpa egiteko tutoriala dela jarraian datorrena. Baina nola egiten da tranpa bakarrik jokatzeko den eta jokalarien sailkapenik ez saririk ez duen joko batean? Wordleren aitzakipean blog honetan GNU/Linuxi buruz zerbait idatzi, eta komando-lerroarekin pixkat jokatzera animatu nahi dut jendea.
Hori argituta, ekin diezaiogun bada artikuluaren mamiari.
Jarraituko dugun estrategiak bi pauso ditu funtsean: lehenik eta behin, euskarazko hitzen zerrenda lortu eta gure ordenagailura deskargatuko dugu. Ondoren, grep komandoa eta adierazpen erregularrak erabiliko ditugu zerrenda laburtu eta bila gabiltzan hitza aurkitzeko. Ziur nago hitzak asmatzeko metodo sofistikatuagoak eta hobeak egon badaudela, baina edonork jarraitzeko moduko tutoriala egitea da nire asmoa.
Euskarazko hitzen hiztegia deskargatzen
Esan bezala, lehenik eta behin, euskarazko hitzen zerrenda eskuratu beharko dugu. Horretarako, Wikimedia fundazioak (Wikipedia ere kudeatzen duena) eskaintzen duen Wikidata datu-base libre eta kolaboratibora joko dugu. Beste informazio interesgarri pila baten artean, euskarazko lexema edo hitzen zerrenda aurkituko dugu bertan. Zerrenda hori deskargatu eta Wordlen komando-lerrotik jokatzeko erabiliko dugu.
Artikulu honetan ez dut Wikidata zer den eta nola erabiltzen den azalduko, gehiago jakiteko orain gutxi Elhuyar aldizkarian argitaratutako artikulu hau irakurtzea gomendatzen dizuet. Dena dela, oraingoz jakin behar dugun gauza bakarra da aukera daukagula zerbitzuari query edo datu eskaerak egiteko.
Kontsulta hau erabiliko dugu datuak deskargatzeko:
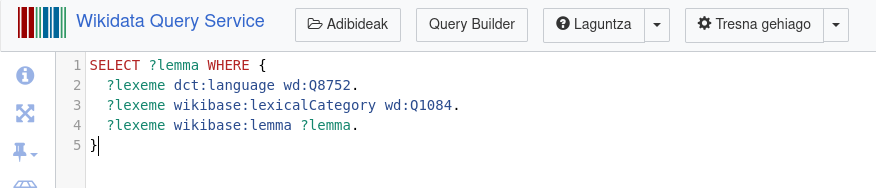
Baliteke batzuei eskaeraren sintaxia oso arrotza egitea, baina funtsean wd:Q8752 hizkuntzaren (hau da, euskararen) , wd:Q1084 motako (sustantiboak) lema guztiak emateko ari gatzaizkio eskatzen Wikidatari. Kontsulta idatzi nahi ez baduzue, egin klik esteka honetan eta irudiko orrialde bera irekiko zaizue.
Behin kontsulta exekutatu dugula “Jaitsi” botoia sakatu, eta “CSV fitxategia” aukeratuko dugu. Hiztegi osoa fitxategi bakarrean deskargatuko zaigu. Oraindik ez ireki fitxategia, laster ikusiko dugu zein itxura duen!
Hiztegia prestatzen
Wordlen jokatzen hasi aurretik, deskargatu berri dugun fitxategia pixka bat aztertzen hasiko gara, eta, horretarako, komando-lerrora salto egingo dugu. Artikulu honetan erabiliko ditugun agindu guztiak nahiko oinarrizkoak dira, eta, beraz, edozein GNU/Linux sistemetan izango ditugu erabilgarri ezer gehigarririk instalatu beharrik izan gabe. Hala ez bada, eta arazorik baduzue, utzi iruzkin bat eta laguntzen saiatuko naiz.
Iritsi da momentua. Ireki komando-lerroa fitxategia deskargatu dugun karpetan eta has gaitezen.
Deskargatu dugun fitxategiak “query.csv” izena du, baina beharbada ez da izen egokiena. “euskarazko-hiztegia.csv” aproposagoa da. Berrizendatu dezagun mv (move) agindua erabilita.
$: mv query.csv euskarazko-hiztegia.csvAgindua ondo exekutatu bada ez da inolako mezurik aterako; aldiz, arazoren bat gertatu bada, errore mezu bat jasoko dugu. Dena dela, berrizendatzea ondo egin dela ziurtatzeko ls (list) agindua erabiliko dugu gauden karpetan dauden fitxategi guztien izenak ikusteko.
$: ls
euskarazko-hiztegia.csv
Agindu hau, edo beste edozeinen erabilera dokumentazioa ikusi nahi badugu, man agindua erabili dezakegu:
$: man mvFitxategiak berrizendatu eta gero, lehenengo lerroak komando-lerroan inprimatuko ditugu zer itxura duen ikusteko.
$: head -n 5 euskarazko-hiztegia.csv
lemma
arbi
damutasun
antzinate
entzimaIkus dezakegu lerroko euskarazko hitz bat daukagula, baina lehenengoa arraroa da. “lemma” euskarazko hitza al da? M bakarra beharrean bi jarri al dizkio norbaitek nahi gabe? Ba ez, “lemma” Wikidatan egin dugun kontsultaren goiburua da. Wikidatak taulak itzultzen ditu, eta guk zutabe bakarreko taula eskatu badugu ere, hor dago goiburua.
Goiburua kentzeko “sed” agindua erabiliko dugu. ‘1d’ bidez lehenengo lerroa ezabatzeko (d/delete) adierazten diogu. "-i" bidez aldiz "sed"i adierazten diogu aldaketa jatorrizko fitxategian bertan aplikatzeko. Azken hori adieraziko ez bagenu, aldatutako fitxategia komando-lerroan inprimatuko litzateke eta ez litzateke fitxategian gordeko.
$: sed -i '1d' euskarazko-hiztegia.csvFitxategiaren azterketa egiten jarraitzeko, daukagun lerro (hau da, hitz) kopurua kontatuko dugu
$: wc --lines euskarazko-hiztegia.csv
14494 euskarazko-hiztegia.csvBaliteke zuei beste lerro kopuru bat agertzea, izan ere, Wikidata datu-base bizia da, eta beraz, baliteke zuek pauso horiek jarraitzean norbaitek hitz gehiago sartu izana.
14494 hitz ditugu, baina denak ez dira baliozkoak. Wordlen 5 letrako hitzak bakarrik erabil daitezke, beraz horiek iragazi behar ditugu. Hori lortzeko "grep" agindua eta adierazpen erregularrak erabiliko ditugu. Adierazpen erregularrak oso konplexuak izan daitezke, baina kasu honetan ahalik eta errazenak erabiliko ditugu. 5 letrako hitzak lortzeko ondorengo blokeko adierazpena erabil dezakegu. Parentesi karratu bakoitzak hitzaren letra bat iragazten du, eta "a-z" bidez esaten diogu letra bakoitza "a" eta "z" arteko edozein karaktere izan daitekeela.
$: grep -o -w "[a-z][a-z][a-z][a-z][a-z]" euskarazko-hiztegia.csv
bedel
berna
akaro
...Esate baterako "a" letraz hasten diren hiru letrako hitzak lortu nahiko bagenitu, honako hau egin genezake:
$: grep -o -w "[a][a-z][a-z]" euskarazko-hiztegia.csv
ara
ahi
ale
...edo "a" eta "b"z hasten direnak:
$: grep -o -w "[ab][a-z][a-z]" euskarazko-hiztegia.csv
boz
ara
ahi
..."grep" aginduarekin gehiago jokatzeko aukera geroago izango dugu. Oraingoz iragazitako 5 letrako hitzak fitxategi batean gordeko ditugu. Agindu baten erantzuna fitxategi batean gordetzeko ">" erabili dezakegu.
$: grep -o -w "[a-z][a-z][a-z][a-z][a-z]" euskarazko-hiztegia.csv > bost-letrako-hitzak.csvEta orain geratu zaigun hitz kopurua kontatu dezakegu.
$: ls
bost-letrako-hitzak.csv euskarazko-hiztegia.csv
$: wc -l bost-letrako-hitzak.csv
1450 bost-letrako-hitzak.csv1450 hitz ditugu beraz Wordlen jokatzeko.
Wordlen jokatzeko garaia
Hiztegia prest dugunez, Wordlen jokatzen has gaitezke. Jokoan sartzen dugun lehenengo hitza edozein izan daiteke, baina hurrengo saiakeretarako pista gehiago izateko ahalik eta letra desberdin gehien dituen hitz bat aukeratzea komeni zaigu. Inspiraziorako gure hiztegitik ausaz hitz batzuk hartu ditzakegu.
$ shuf -n 5 bost-letrako-hitzak.csv
bario
portu
ezbai
herra
hunkiAdibide bezala "bario" hartuko dugu, eta jokoan sartu.
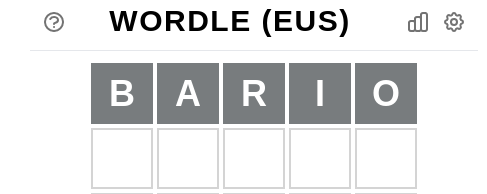
Zorte txarra izan dugu, eta letra bakar bat ere ez dugu asmatu. Dena dela, orain badakigu letra horiek ez dituzten hitzak behar ditugula. Berriro "grep" komandora joko dugu baldintza hori iragazteko. Lehengo antzeko adierazpena erabiliko dugu, baina "^" ikurra erabilita esango diogu "b","a","r","i","o" letrak ezin direla posizio bakar batean ere egon.
$: grep "[^bario][^bario][^bario][^bario][^bario]" bost-letrako-hitzak.csv
eztul
negel
menpe
...Horrek hitz zerrenda luze bat itzuliko digu. Lortutakoak kontatzeko fitxategi batean gorde (">" erabilita) eta lerroak konta genitzake ("wc -l" erabilita). Baina hori baino errazagoa da "grep" aginduaren erantzuna zuzenean "wc" aginduari bidaltzea "|" erabilita. Pipeline deitutako ezaugarri honi esker (edozein agindurekin erabili daitekena) fitxategi berriak sortzea ekidin dezakegu agindu baten irteera bestearen sarrerara bidalita.
$: grep "[^bario][^bario][^bario][^bario][^bario]" bost-letrako-hitzak.csv | wc -l
55Hurrengo hitza aukeratzeko berriro ausazko batzuk har ditzakegu iragazitako zerrendatik
$: grep "[^bario][^bario][^bario][^bario][^bario]" bost-letrako-hitzak.csv | shuf -n 5
eztul
fuste
menpe
lehen
plegu"plegu" hitza aukeratuko dugu, ea zorterik dugun.

Zorte handirik izan gabe jarraitzen dugu, baina orain badakigu bila gabiltzan hitzak "e" eta "u" letrak izan behar dituela. Gainera, 3. posizioan "e" letrak ez duela egon behar, eta 4.enan "u"k ere ez. Baita "p", "l" eta "g" letrek ez dutela posizio bakar batean ere egon behar. Hori lortzeko adierazpen erregular bakarra erabili beharrean, adierazpena idaztea errazteko hainbat erabil ditzakegu aurreko pausoan ikusi dugun "|" erabilita. Horrela lehenengo egon ezin duten letrak iragaziko ditugu, ondoren "e" ez dutenak, eta azkenik "u" ez dutenak.
$: grep "[^plgbario][^plgbario][^eplgbario][^plgbario][^uplgbario]" bost-letrako-hitzak.csv | grep e | grep u| wc -l
5
$: grep "[^plgbario][^plgbario][^eplgbario][^plgbario][^uplgbario]" bost-letrako-hitzak.csv | grep e | grep u
zuzen
sujet
numen
fuste
ezune
Dagoeneko zerrenda 5 hitzetara jaitsi dugu. Horietatik "zuzen" aukeratuko dugu. Zuzena ote?

Asmatu gabe jarraitzen dugu, baina gertuago gaude. Bi letraren posizioa behintzat asmatu dugu. Iragazkiak berriro moldatuko ditugu.
$: grep "[^znplgbario][u][^zneplgbario][e][^znuplgbario]" bost-letrako-hitzak.csv
sujetHitz bakarra geratu zaigu. Hori izango al da? Edo gure hiztegian falta den hitz bat ote?
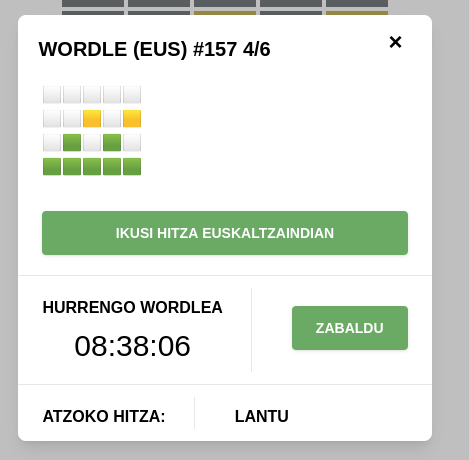
Asmatu dugu! Hitz ezohikoa dudarik gabe, baina hiztegian badagoena, noski.
Eta honekin amaitutzat joko dugu Wordlen komando-lerroaren laguntzareko jokatzeko tutoriala. Helburu bera lortzeko beste hamaika metodo eta adierazpen erregular desberdin daude, beraz segi jokatzen eta ea nora iristen zareten!



Iruzkinak